이 포스터에선 그래프와 관련된 기본적인 알고리즘을 소개하도록 하겠다.
그렇다면 그래프(Graph)가 무엇인가?
그래프(Graph)

그래프는 노드(Node)와 간선(Edge)로 구성된 집합이다.
노드는 데이터를 표현하는 단위이고 간선은 노드를 연결한다.
그래프는 여러 알고리즘에서 많이 사용되는 자료구조이다.
그래프 알고리즘
그래프 자료구조를 활용한 대표적인 알고리즘은 다음과 같다.
- 유니온 파인드: 그래프에 사이클이 존재하는지 판별하는 알고리즘
- 위상 정렬: 그래프를 선형 정렬한다. 사이클이 없는 방향 그래프에서 사용한다.
- 다익스트라: 시작점을 기준으로 모든 노드를 방문하는 최소 비용을 구한다. (음수 간선 포함 X)
- 벨만-포드: 시작점을 기준으로 모든 노드를 방문하는 최소 비용을 구한다. (음수 간선 포함 O)
- 플로이드-워셜: 모든 모드에 대해 모든 노드를 방문하는 최소 비용을 구한다.
- 최소 신장 트리: 모든 노드를 연결하는 최소 비용의 트리를 구한다.
나중에 각 알고리즘에 대해 자세히 포스팅하도록 하겠다.
그래프의 표현
그래프를 표현하기 위해서 어떤 방식의 자료구조로 저장할 지가 중요하다.
그래야지 위에서 언급한 알고리즘들을 구현할 수 있다.
이 포스터에선 3가지 방법에 대해 알아보도록 하겠다.
1. Edge List

Edge에 대해 (Start, End) Tuple로 저장하는 방법이다.
만약 방향이 없는 그래프의 경우, 하나의 Edge를 2개로 번갈아 저장한다.
예를 들어 (1번 노드) - (2번 노드) Edge 하나를 저장하려면
(1, 2), (2, 1) 2개를 저장하는 것이다.

Edge에 대해 (Start, End, Weight) Tuple로 저장하는 방법이다.
만약 방향이 없는 그래프의 경우, 위와 마찬가지로 번갈아 저장하면 된다.
Edge List는 Edge 중심의 알고리즘인 벨만 포드나 크루스칼(MST) 알고리즘에 사용된다.
3. 인접 행렬
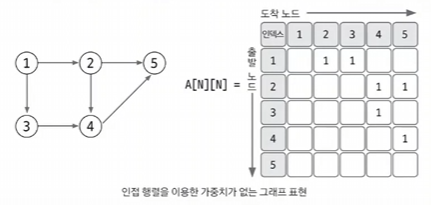
인접 행렬은 Node 기반으로 저장하는 자료구조이다.
Index는 start, end로 표현하며, Element는 weight에 해당한다.
만약 weight이 존재하지 않다면 1로 표시해둘 수 있다.

이 방법은 Edge을 탐색하려면 N번 접근해야 하므로
노드 개수에 비해 Edge가 적을 때 공간 효율성이 떨어진다.
따라서 노드 개수가 많은 경우 사용 여부를 적절하게 판단해야 한다.
(노드의 개수가 적을 때 사용하면 좋음)
4. 인접 리스트 (★)

인접 행렬의 공간 효율을 높인 자료구조이다.
각 노드에 대해 리스트 자료구조로 구성되어 가변적이다.
만약 가중치가 없다면 Int로 저장해주면 된다.

만약 가중치가 있다면 pair<int, int>으로 저장해주면 된다.
first는 end, second는 weight으로 저장해준다.
혹은 pair 대신 node class를 제작하여 대신할 수 있다.
'IT > 알고리즘' 카테고리의 다른 글
| [C++] 위상 정렬 (Topological Sort) (0) | 2023.11.15 |
|---|---|
| [C++] Union-Find (1) | 2023.11.14 |
| [C++] 유클리드 호제법 (최대 공약수 & 최대 공배수) (1) | 2023.11.13 |
| [C++] 오일러 피 (서로소) (0) | 2023.11.10 |
| [C++] 소수 구하기 (에라토스테네스의 체) (4) | 2023.11.10 |