📌 개요

Unity에서 게임을 만들다보면 특정 리스트에서 중복 없이 랜덤 요소를 뽑는 기능이 자주 필요하곤 합니다.
아마 대부분은 다음과 같은 방법으로 로직을 작성할거라 생각합니다.
- List 중복 체크 방법
- List 중복 제거 방법
- HashSet 자료구조 활용

결론부터 말하자면...
(일반적으로) HashSet 자료구조를 사용하는게 좋습니다.
[ HashSet 을 활용한 코드 보기 ]
private List<T> GetNotDuplicateRandomList_HashSet<T>(IList<T> list, int count)
{
HashSet<T> hashSet = new HashSet<T>(list);
List<T> uniqueList = hashSet.ToList();
List<T> result = new List<T>();
int n = uniqueList.Count;
// count > n => error!
for (int i = 0; i < count; i++)
{
int r = UnityEngine.Random.Range(i, n);
T temp = uniqueList[i];
uniqueList[i] = uniqueList[r];
uniqueList[r] = temp;
result.Add(uniqueList[i]);
}
return result;
}
그렇다면 왜 HashSet을 사용하는 것이 좋은지 실험을 통해 살펴보도록 하겠습니다.
☑️ 알아두기! HashSet 자료구조란?
C# HashSet은 내부적으로 Hash Table을 사용하여 구현된 컬렉션입니다.
System.Object.GetHashCode 값을 기반으로 HashKey을 생성하여 Value을 저장하는 형태로,
요소 추가 및 삭제, 탐색 모두 상수 시간 복잡도(O(1))을 가집니다.
중복된 Key을 허용하지 않기 때문에 중복 제거 기능으로 활용할 수 있습니다.
📌 결과 분석
실험을 위해 3가지 형태의 랜덤 리스트 뽑기 기능을 제작하였습니다.
- List 중복 체크 방법 (CheckDuplicate)
- List 중복 제거 방법 (Remove)
- HashSet 자료구조 활용 (HashSet)
[ 실험을 위해 사용된 코드 ]
using System.Collections.Generic;
using UnityEngine;
using System.Linq;
using System;
namespace DevelopKit
{
public class RandomListTester : MonoBehaviour
{
/// 테스트용 리스트 데이터
List<int> testList1;
List<int> testList2;
List<int> testList3;
List<int> data;
int count;
int findCount;
int testCount;
float checkDuplicateTime;
float removeTime;
float hashSetTime;
private void Start()
{
testList1 = Enumerable.Range(1, 1000).SelectMany(x => Enumerable.Repeat(x, 1000)).OrderBy(x => UnityEngine.Random.value).ToList();
testList2 = Enumerable.Repeat(0, 9999999).Concat(new[] { 1 }).ToList();
testList3 = Enumerable.Range(1, 1000000).OrderBy(x => UnityEngine.Random.value).ToList();
data = testList3;
findCount = 10000;
float startTime, endTime;
for (int k = 0; k < 1; k++)
{
testCount++;
startTime = Time.realtimeSinceStartup;
GetNotDuplicateRandomList_CheckDuplicate(data, findCount);
endTime = Time.realtimeSinceStartup;
checkDuplicateTime += endTime - startTime;
startTime = Time.realtimeSinceStartup;
GetNotDuplicateRandomList_Remove(data, findCount);
endTime = Time.realtimeSinceStartup;
removeTime += endTime - startTime;
startTime = Time.realtimeSinceStartup;
GetNotDuplicateRandomList_HashSet(data, findCount);
endTime = Time.realtimeSinceStartup;
hashSetTime += endTime - startTime;
}
Debug.Log("--------------------------------");
Debug.Log($"Test Count: {testCount}");
Debug.Log($"Check Duplicate Time: {checkDuplicateTime}");
Debug.Log($"Remove Time: {removeTime}");
Debug.Log($"HashSet Time: {hashSetTime}");
}
private List<T> GetNotDuplicateRandomList_CheckDuplicate<T>(IList<T> list, int count)
{
List<T> result = new List<T>();
for (int i = 0; i < count; i++)
{
int index = UnityEngine.Random.Range(0, list.Count);
while (result.Contains(list[index]))
index = UnityEngine.Random.Range(0, list.Count);
result.Add(list[index]);
}
return result;
}
private List<T> GetNotDuplicateRandomList_Remove<T>(IList<T> list, int count)
{
List<T> result = new List<T>();
List<T> temp = new List<T>(list.Distinct());
if (count > temp.Count)
count = temp.Count;
for (int i = 0; i < count; i++)
{
int index = UnityEngine.Random.Range(0, temp.Count);
result.Add(temp[index]);
temp.RemoveAt(index);
}
return result;
}
private List<T> GetNotDuplicateRandomList_HashSet<T>(IList<T> list, int count)
{
HashSet<T> hashSet = new HashSet<T>(list);
List<T> uniqueList = hashSet.ToList();
List<T> result = new List<T>();
int n = uniqueList.Count;
for (int i = 0; i < count; i++)
{
int r = UnityEngine.Random.Range(i, n);
T temp = uniqueList[i];
uniqueList[i] = uniqueList[r];
uniqueList[r] = temp;
result.Add(uniqueList[i]);
}
return result;
}
}
}
이제 실험을 분석해보도록 하겠습니다.
문제 상황은 총 3가지 이며, 각 상황에 따라 CheckDuplicate, Remove, HashSet 방식의 성능 차이를 분석했습니다.
☑️ 문제 상황 1. 정렬 X, 중복 X (일반적인 상황)
data = Enumerable.Range(1, 1000000).OrderBy(x => UnityEngine.Random.value).ToList();
숫자 1 ~ 100만개로 이루어진 정렬되지 않은 List<int> 데이터입니다.
이 데이터에서 랜덤값 10000개를 추출한 결과는 다음과 같습니다.

실험을 단 한번 수행했을 때 결과를 분석해보면,
- HashSet이 CheckDuplicate보다 약 3.9배 성능이 좋습니다.
- HashSet이 Remove보다 약 14.7배 성능이 좋습니다.
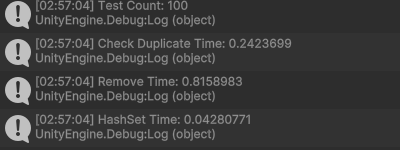
실험을 100번 수행했을 때 결과를 분석해보면, (평균값)
- HashSet이 CheckDuplicate보다 약 5.66배 성능이 좋습니다.
- HashSet이 Remove보다 약 19.0배 성능이 좋습니다.
☑️ 문제 상황 2. 정렬 X, 중복 O
data = Enumerable.Range(1, 1000).SelectMany(x => Enumerable.Repeat(x, 1000)).OrderBy(x => UnityEngine.Random.value).ToList();
숫자가 1 ~ 1000이 각각 1000개씩 존재하며, 정렬되지 않으며 중복이 존재하는 List<int> 데이터입니다.
이 데이터에서 랜덤값 10000개를 추출한 결과는 다음과 같습니다.

실험을 단 한번 수행했을 때 결과를 분석해보면,
- HashSet이 Remove와 비슷하며, Check Duplicate 보다 성능이 2배 낮습니다.

실험을 100번 수행했을 때 결과를 분석해보면, (평균값)
- 위와 동일합니다.
HashSet은 Hash Table이기 때문에 메모리가 분산되어 있습니다.
이 요소(Entry) 모두를 하나의 List로 만드는 비용에서 차이가 발생했다고 생각합니다.
해당 데이터 셋이 균등하기 때문에 탐색 비용이 가장 적었을 것이며,
자료구조를 구축하는 HashSet 생성 비용과 비교했을 때 불리한 상황이라고 생각합니다.
☑️ 문제 상황 3. 편파적인 데이터 (극단적인 상황)
data = Enumerable.Repeat(0, 9999999).Concat(new[] { 1 }).ToList();
숫자 0이 999만 9999개, 숫자 1이 단 1개인 List<int> 데이터입니다.
이 데이터에서 랜덤값 2개를 추출한 결과는 다음과 같습니다.
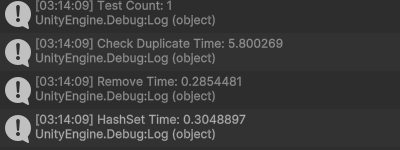
실험을 단 한번 수행했을 때 결과를 분석해보면,
- CheckDuplicate가 성능이 압도적으로 낮았습니다.
- HashSet과 Remove 성능이 비슷합니다.
전체적인 양상을 살펴봤을 때, 일반적으로 HashSet을 활용하는 것이 좋은 것 같습니다.
만약 더 좋은 로직이 있다면 댓글로 공유해주시면 감사하겠습니다.
💡 참고 자료
[ Microsoft 공식 문서 ]
HashSet<T> 클래스 (System.Collections.Generic)
값 집합을 나타냅니다.
learn.microsoft.com
'
'유니티(Unity) > 이론 정리' 카테고리의 다른 글
| [Unity] 카메라와 컬링 (2) | 2024.12.13 |
|---|---|
| [Unity] Model이 렌더링(Rendering)되는 과정 (1편) (0) | 2024.11.21 |
| [Unity] URP란 무엇인가? (0) | 2024.11.20 |
| [Unity] 직렬화(Serialization)란 무엇인가? (1) | 2024.11.19 |
| [Unity] Mono & IL2CPP 컴파일 방식의 차이 (0) | 2024.11.18 |